URL Shortening Service - TinyURL Design
TinyURL is a URL shortening web service, which provides short aliases for redirection of long URLs.
|
We will discuss the following |
|---|
|
|
Requirements
The first step would be to collect the functional and non-functional requirements of the service.
Functional Requirements
The functional requirements include:
1. Given a big URL, the service should generate a unique small URL (or link) for the big URL (this is a write operation).2. When provided a short URL, the service should redirect the user to the big URL, or else return "not found" if the big URL does not exist (this is a read operation).
3. The length of the short URL should be at most 6 characters (of course, in the future, we can increase the length to 7, 8, or more characters, if needed. However, we will see that even with 6 characters, we can generate a very large number of unique short URLs).
4. The generated short URL should be somewhat random. This is not a hard requirement, though, as we do not see why it would be bad for the service if someone can guess the next generated short URL. Let us know in the comments what do you think why it would be bad for the service if someone can figure out the next generated short URL.
5. If two users try to create a short URL for the same big URL, the service should return different short URLs.
- Free users - who can create up to a certain number (e.g., up to 10) of short URLs with some default expiration time (e.g., one month)
- Premium users (or paying users) - who can create up to a certain number of short URLs which is much bigger than 10 (e.g., 100 or 1000 or 10000) and also with a longer expiration time (e.g., the expiration time in years, or never gets expired as long as the user is a premium user)
- This requires having an analytics and monitoring component.
Non-Functional Requirements
The non-functional requirements include:
1. The service should be highly available (e.g., having 99.999% or five 9s).
2. The service should be fault-tolerant.
- What it means that, in case of faults and/or failures, the service should still be available to serve the users
3. The read and write operations (i.e., creating short URLs from big URLs and redirecting users to big URLs from short URLs) should occur with minimal latencies.
- maybe in the order of a few milliseconds (e.g., up to 500 msec at most)
4. The service is scalable with increasing load.
5. Minimum cost possible - it dictates that the system should start with few servers to minimize the cost but should be elastic enough to scale with increasing user load.
6. The service has strong consistency in the sense that once we created and returned a short URL to the user, if the user queries the big URL using that short URL, the service should be able to return the big URL.
7. At the same time, we also want data to be durable. So, once a short URL has been created, it should be present in the system during its lifetime (i.e., before its expiration time).
Of course, some of the non-functional requirements are somewhat related. E.g.
- the service cannot be highly available if it is not fault-tolerant
- similarly, the service cannot have minimal latencies if it is not scalable with increasing load
We are restricting the functional and non-functional requirements to only the above set, although there can be more requirements. These requirements will dictate how we are going to design our service.
Application Programming Interface (API)
The service will support the following set of APIs.
The first set of APIs is related to user logon/logoff.
userLogon ()
This API returns the user token after authenticating the user.
userLogoff ()
💬 We will not discuss how the user logon/logoff APIs work in this chapter. We might add a separate chapter on designing the Identity and Access Management System to discuss these APIs in the future.
The service will use an external Identity Provider, such as Facebook or Google (i.e., the user can use his Facebook or Google account to login to the service).
Now, Let's discuss the other set of APIs that are related directly to our service functionality. There are two operations that we are performing: one creating a short URL for a big URL and second retrieving a big URL from the short URL. So, there will be following two APIs that our service will provide:
createShortURL (userToken, bigURL, optional expirationTime)
This API takes a big URL and an optional expiration time as an input, and then creates and returns a unique short URL. Here, the userToken is returned by the logon API and is used to get the user identifier. The user identifier is then used to determine whether the user is a free user or a premium user. Based on this, we can decide whether the user has reached his allocated quota for the short URLs or not. It can also be used to throttle a user based on his allocated quota.
getBigURL (shortURL)
This API returns the big URL given a short URL if it exists.
High-Level Design
In a simple design, the user will be talking to a single application server in our service. That application server will be storing the mapping between the short URLs and the big URLs in the database locally. However, this design has several flaws. It is not scalable as a single server cannot handle 10s to 100s of thousands of requests per sec. Also, neither the design is fault-tolerant, nor the service is highly available. This single server can go down at any time when some failure happens. It can also go down for periodic maintenance, thus affecting the availability of the service.
 A simple architecture
A simple architecture
Obviously, even though the design can fully serve the functional requirements, it cannot meet the non-functional requirements. This clearly shows that the non-functional requirements are an important factor in dictating the design of a service.
Now consider the following design:
 A preferable architecture
A preferable architecture
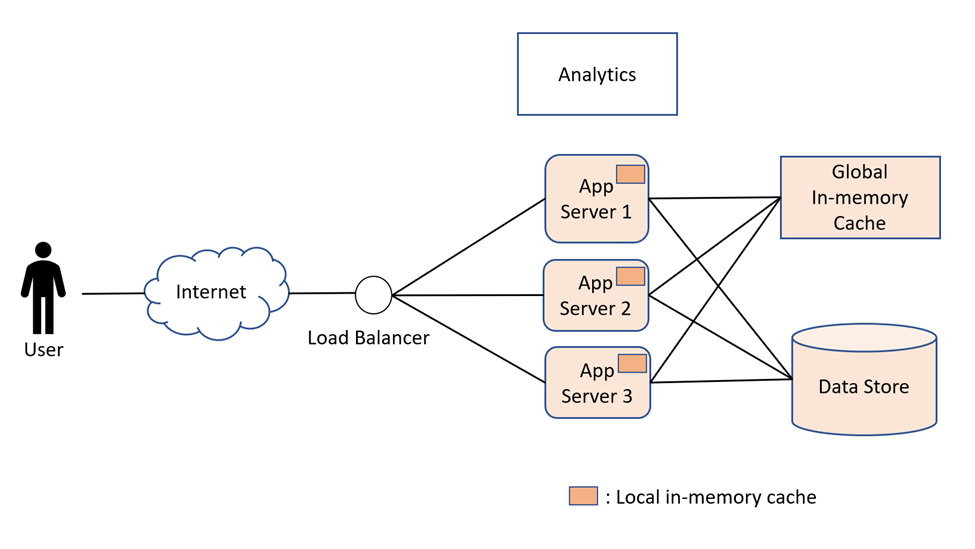
Here, we have a minimum of three application servers that serve the users' read/write requests. The users talk to the app servers via a load balancer. The load balancer distributes the read/write requests among the servers equally in a round-robin fashion. We are using a minimum of three application servers. Reason being that using two app servers is not enough to ensure that the service remains highly available at all times. It is possible that one server could be down for some time, for some periodic maintenance (e.g., host OS patching or deployment of new service builds). During that time, there is always a possibility of the single working server getting a failure, thus causing service unavailability. This is the reason we use at least three app servers. The periodic maintenance is done on one server at a time to avoid the possibility of a situation where only a single server is serving the read/write requests.
This design is also highly scalable. We will be monitoring each server. As the resource consumption in each server crosses above some threshold (e.g., 80% of CPU usage or the number of read/write requests per second cross 10K requests per server), we can add more servers and configure the load balancer to send requests to the new servers as well. Also, if the resource consumption goes below a certain threshold (e.g., less than 30% of CPU and/or the number of requests below 1K requests per second), we can remove servers to minimize the cost. Similarly, if a server dies, we can remove it from the load balancer as well.
The load balancer can also use different mechanisms other than round-robin to decide which server to forward the request to. This we will discuss later in future chapters.
Datastore:
By introducing at least three app servers, we have tried to ensure that the service's design is highly available and scalable. However, the overall service design cannot be highly available, scalable, and durable if the datastore used is not highly available, scalable, and durable. The data store needs to exhibit these properties for the overall service to exhibit these properties. We will discuss the design of the datastore in a future chapter in detail.
In-Memory Cache:
The number of read requests would be much higher than the number of write requests. Initially, we can safely assume that the number of reads is at least 10x the number of writes. Since we also have an analytics and monitoring component to measure the number of read/write requests, we can determine the correct ratio between read and write requests. However, it is for sure that the number of reads will be much higher than the number of writes. So, we can introduce an in-memory cache to store the mapping between the short and big URLs to reduce requests hitting the datastore for reading.
Now there are two approaches to use an in-memory cache. The first approach is that each app server has its own local in-memory cache and the second approach is to use a global in-memory cache. The advantage of the first approach is that accessing a local in-memory cache has way less latency than accessing a global cache (which would be maintained in separate cache servers). If the number of app servers is less than 5, then it would be better to have a local in-memory cache because we would be hitting the datastore only at most 5 times for each short URL (one from each server). Afterward, all the read requests can be returned directly from the local in-memory cache. However, as the number of app servers is increased to a substantial number, having only the local in-memory cache will cause the read request to hit the datastore more often (up to the number of app servers) for each short URL mapping. In this case, we could introduce a global in-memory cache (e.g., Memcache, etc.). Whether it is a local or global in-memory cache, it could use the least recently used (LRU) as an eviction policy when the cache has reached its maximum size.
Detailed Design
Key/Short URL Generation:
The first thing we will discuss is how the short URL will be encoded. We have different encoding mechanisms that we can use.
- If we use base62 (0-to-9, a-to-z, A-to-Z) then we can encode up to 62 ^ 6 = 56.8 billion short URLs
- If we use base64 (0-to-9, a-to-z, A-to-Z, -, _) then we can encode up to 64 ^ 6 = 68.7 billion short URLs
⚠ Some online resources discuss using ‘+’ and ‘/’ characters in base64 encoding. Please note these characters are unsafe for use in an HTTP request. And so, if you are using them, then you need to encode ‘+’ and ‘/’ as ‘%2B’ and ‘%2F’ respectively, but this will increase the size of the short URL to more than 6 characters. We will use base64 encoding with characters (0-to-9, a-to-z, A-to-Z, -, _).
Now, let us discuss how the short URL will be generated. There are different mechanisms of generating short URLs that have been discussed by other online resources, including some other YouTube videos and online books/courses on system design interviews.
The first mechanism is using the MD5 hash of the big URL. The MD5 hash produces a 128-bit hash value. If we encode 128-bit MD5 hash into base64, we need 22 characters to fully encode the 128-bit hash value. Since the requirement is to generate up to 6 characters, it means we must drop 16 characters from the encoding either at the beginning or at the end. However, this would result in many collisions for different big URLs, especially if several users try to create a short URL for the same big URL. This clearly suggests that using MD5 hash or any other hash function is not feasible from the requirements perspective.
Then some other online resources have suggested using the zookeeper to maintain a range of counter values that each app server can use for generating short URLs. However, this adds extra complexity to the design as now you also need to maintain another service. Also, the zookeeper needs to update those ranges when they are exhausted. This will also add to the system's overall cost, and what you want to achieve with the zookeeper can be achieved without using it, as we will discuss later.
Then some other online resources have suggested using a key-generation service (KGS), which generates unique short URLs and returns them to the app servers. However, this just moves the design complexity of generating a unique short URL to a different service. Then, we need to discuss how this KGS is designed and whether KGS comprises a single server or more. If a single server, this breaks our non-functional requirements around availability, scalability, durability, etc. If KGS has more than one server, it adds lots of complexity to KGS service's design that how the KGS service will be generating unique keys and passing them to the app server when several app servers contact KGS service. Whether all the requests, from different app servers, go to a single server in KGS service (which means that the single server becomes a bottleneck for the service) or goes to multiple servers in KGS service (if that is the case, then how different KGS servers coordinate to only provide unique short URLs to different app servers). It also adds an extra dependency on a different service in our design, and this different service (i.e., KGS) is needed to be maintained as well.
In short, we do not need to rely on a zookeeper or a separate key generation service. We can generate unique short URLs as follows. In our data store, we are storing a counter key-value. Now when an app-server comes up, it will go to the datastore and read and increment this counter value in a database transaction by some increment value. The increment value could be passed to the server as a starting configuration and could be 10, 100, or 1000. Let us take 100 as an example increment value right now. Now when after reading and incrementing the counter by 100 when the app server commits the transaction successfully, then it can safely assume that it can use all the counter values starting from the read value up to read value plus 99 for generating short URLs.
Consider an example below, where we have three app servers, and in the datastore, the counter value is 1.
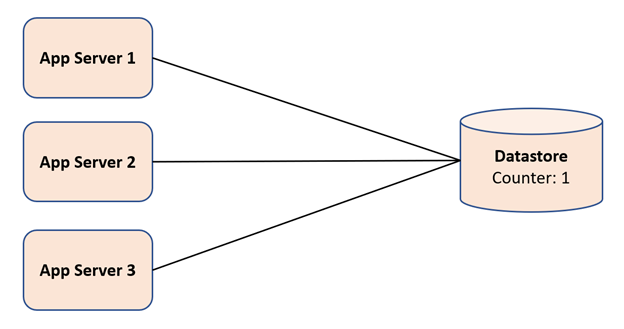
Now first app server 1 goes to the datastore and read the counter value of 1 and increment the counter value from 1 to 101 in a database transaction. If the transaction is successful, then app server 1 can safely assume that it can generate short URLs using counter values 1 to 100. When it exhausts all these values, it will go again to the datastore to read the next set of counter values.

After app server 1, app server 2 goes to the datastore and reads and increments the counter's value by 100 in a database transaction. This time app server 2 will read the value of 101 and increment the counter value in the datastore to 201. Thus, it can safely assume that it can use values from 101 to 200 for short URL generation.

After app server 2, app server 3 goes to the datastore and reads and increments the counter's value by 100 in a transaction. This time app server 3 will read the value of 201 and increment the counter value in the datastore to 301. Thus, it can safely assume that it can use values from 201 to 300 for short URL generation.
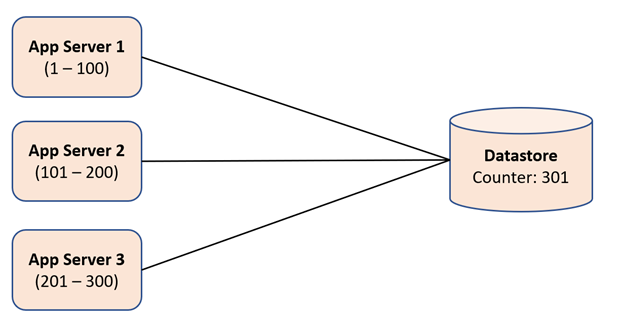
Now, when one of the above servers exhausts all his counter values, then it will go to the datastore again and try to read and increment the counter value in the datastore in a database transaction. E.g., if now app server 2 goes to the datastore, it will read the value of 301 and increment the counter to 401 in the datastore. It can then safely assume that it can use counter values from 301 to 400 to generate short URLs.
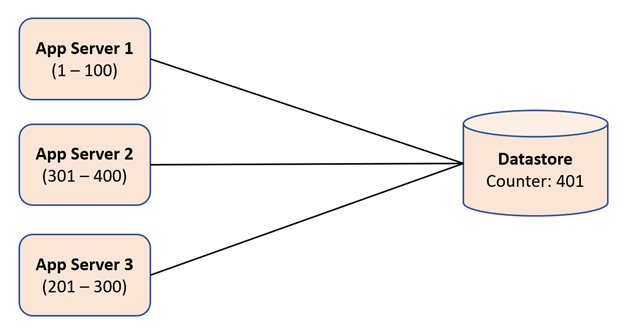
The important thing here is that each app server will try to read and increment the value in a database transaction. This is important for the case when two app servers try to read and increment the value of the counter at the same time. In this case, one app server will succeed in committing the transaction and can use the read counter value to generate short URLs. However, the other app server will get 'commit conflicts' while committing the transaction, and it needs to retry again to read and increment the counter in the database. It seems like reading and incrementing the counter value in the data store is a bottleneck, but this is not the case. Since we are incrementing the counter value by 100, each app server only goes to datastore after generating 100 short URLs locally. Instead of a key-value, we can also use a database construct called "Sequence" or "Auto-increment Counter" found in different databases like Oracle DB, MongoDB, Cassandra, etc.
There is one issue in this design, though. There is a possibility of losing up to 100 short URLs if the app server somehow crashes after reading the next counter value. However, this is tolerable as we can generate up to 68.7 billion short URLs. The other mechanisms, like using a zookeeper or a key generation service, also have the same flaws.
Now, this counter value (which is a decimal integer) can be easily converted to a base64 number as follows (considering we have the following mapping of decimal integer to base64 number):
Decimal Integer |
Base64 encoded number |
0 - 9 |
0 - 9 |
10 - 35 |
a - z |
36 - 61 |
A – Z |
62 |
- (dash) |
63 |
_ (underscore) |
Decimal integer 1 can be converted to 1 in base64 encoded number and precisely to 000001 if we want to have at least 6 digits of base64 encoded number. Similarly, decimal integer 10 can be converted to 00000a in base64 number.
❔ This is left as an exercise to the reader to come up with the code to convert a decimal integer to a base64 number.
💡 We can map decimal integers to different unique base64 encoded numbers randomly if we need to introduce some randomness. E.g., 0 can be mapped to Z, 1 to a, 2 to G, 3 to f, 10 to C, 11 to v, and so on, etc. This will then appear to the normal users that the generated short URLs are totally random.
Database Design
There are two types of databases that we could use for our datastore, either a relational database or a NoSQL database. However, as we have discussed before that the non-functional requirements dictate that the datastore needs to be highly available, scalable, performant, and durable. Also, the database schema required for our service does not have any relations requiring relational databases. Thus, a NoSQL database seems to be the best choice for the datastore. The relational databases are usually not that highly available and performant and only support vertical scaling. The following will be two tables (sometimes called buckets in several databases) that we need.
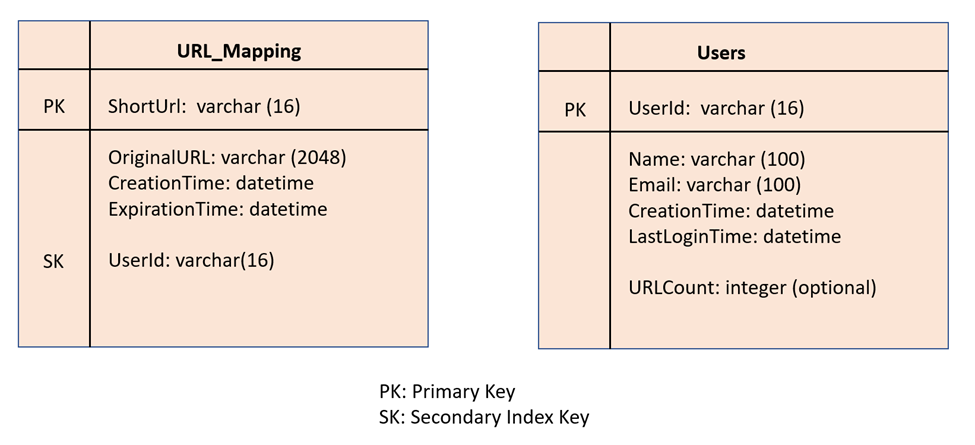
Since we are now using a NoSQL database, we have two choices. Either we use a simple key-value datastore or use an advanced key-value datastore like document datastore. One difference between simple key-value datastore vs. document datastore is that key-value datastore only allows retrieving a record by its key value as the record structure is opaque to the datastore. While document datastore extends the previous model and records are stored in a structured format that the database can understand. Thus, the document datastore can have secondary indexes on other columns. E.g., document datastore can have a secondary index on the UserId in the URL_Mapping table, which we can then use to retrieve all the short URLs created by a user.
So, if there is no requirement to retrieve all the short URLs created by a user, we can simply use a key-value datastore. However, document datastore will give us more flexibility if we also need to retrieve all the short URLs created by a user in the future.
Also, check that the Users table has an optional column for URLCount, which is the count of short URLs created by the user. If we do not need to maintain this count, then creating a short URL only requires generating a short URL and then storing the mapping between the short and the big URL in the URL_Mapping table. Since we are already ensuring that the short URL generated by an app server is unique, we do not even need to use a database transaction to store the mapping in this bucket. However, if we also need to increment the count of short URLs created by the user, then we need to update both the tables, and then we require to do that in a database transaction as follows:
Generate short URL
Open datastore transaction
Write to URL_Mapping table
Read user information from Users table using userId
Increment the URLCount and update user information in the Users table
Commit transaction
The database transaction will enable us to update both the tables atomically in the sense that either write to both the tables will succeed, or both will fail, thus not leave the datastore in an inconsistent state. These design decisions will affect the datastore that we will choose to store the URL mapping and user information. If a NoSQL database does not provide a transaction guarantee to update the records in both the tables then we need to either choose a relational database or find some other mechanism to increment the URLCount. One approach is to add the operation in a persistent queue and then process the messages in the queue to increment the URLCount. However, in this case, the URLCount update operation has an eventual consistency.
This is how the write operation will happen in our service. Now let us discuss how the read operation will happen in our service, i.e., how the service returns a big URL given a short URL. When an app server receives the read request from the user, it will first check the in-memory cache with the short URL key (either local or global cache). If it is present in the cache, it will check whether the short URL is expired or not. If not expired, then it will return the big URL corresponding to the short URL from the mapping entry in the cache. If the mapping is not present in the cache, then the app server will go to the data store and read the mapping from there, store it in the cache and return the big URL to the caller/user.
How will we scale the datastore?
We scale the datastore by partitioning it. The URL_Mapping table can be partitioned by the ShortURL as the partition key. Now there are two approaches to partition the table.
- Hash-based partitioning – we partition the database by the hash of the partition key.
- Range-based partitioning – we store short URLs in the partitions by certain ranges. E.g., we can decide to store short URLs from “000001” to “00ZZZZ” in one partition, “010000” to “01ZZZZ” in another partition, and so on.
If we look closely at both the above partitioning scheme, then we can realize that for our purpose, the hash-based partitioning scheme is better because the generated short URLs will be uniformly distributed across all the partitions. If we use a range-based partitioning scheme, then due to the way we are generating the short URL via a counter value, all the writes will always go to a single database partition, thus resulting in one partition as always write-heavy. Most of the time, the short URL is accessed/read more frequently just after it is created. So, most of the read requests will go to the same partition as well. Thus, a range-based partitioning scheme is not suitable as it will result in all writes and most reads to go to a single partition, making that partition a hot spot. On the other hand, using a hash-based partitioning scheme will result in short URLs uniformly distributed across all partitions. This will result in reads/writes to be distributed uniformly across all the partitions.
Similarly, the User table can be partitioned by the hash of the UserId.
How do we purge the database?
Since we are creating a short URL to big URL mapping with an expiration time, we need a mechanism to delete the expired short URL mappings. We can have two approaches to this.
1. The first approach is that the expiration time is only used during a getBigUrl() call to check whether the URL mapping is expired or not. If expired, then only at that time we delete the mapping record from the database. Of course, with this approach, there could be dangling URL mappings that will remain in the database after their expiration. This will be an extra waste of storage. The question would be whether we can live with this wastage of storage or not.
2. The second approach is that we run some background jobs periodically (maybe once a month) that goes through all the URL mapping records to see which URL mappings have expired and then deletes those records. The background jobs could run for each partition where they only scan and delete the expired URL mappings in that partition. However, this now requires that we use a datastore, which also supports the scanning of tables (range queries). Now we cannot use a simple key-value datastore that provides put() and get() calls but does not support scan().
Global Cache vs. Local Cache
We have already discussed in some detail about whether to use a local cache or a global cache to minimize load on our datastore. Here for completion, we would like to discuss one scenario where we will prefer a global cache over a local cache. Consider the case where you start receiving a large number of requests for some short URL that has not yet been created. It could be because of a malicious user trying to perform a denial of service (DOS) attack. So, you will not find that URL in your in-memory cache, and then you will go to datastore for every request for such a short URL. This will cause unnecessary stress on your datastore. To avoid this stress, you could store a sentinel value in the in-memory cache for that short URL, informing that this short URL does not yet have any big URL mapping. And so instead of going to the datastore, you can return "not found" after checking your in-memory cache if you see that sentinel value. However, this now requires you to remove this sentinel value from the cache if that short URL is used in creating a URL mapping. This removal is only possible in the case of a global cache where the create request could come to any server, and that server can invalidate (or remove) the sentinel value from the global cache. If we would have used a local in-memory cache, then we cannot use the sentinel value in the local in-memory cache. The reason being if the same short URL is now used to create a short URL to big URL mapping, then we need to invalidate this short URL entry in the local in-memory cache. Since the local in-memory cache is local to each app server, the app server that receives the write request cannot go and invalidate the in-memory local cache of all the other app servers. This will cause a consistency problem in our service if the read request now goes to an app server, which has this sentinel value stored in its local in-memory cache, suggesting that the short URL mapping is not present. This app server will return "big URL not found", which would be an incorrect response. We have another choice to use both the local and global cache but store the sentinel values only in the global cache.
💬 We did not discuss the internals of how a datastore is highly available, scalable, durable, etc. We also did not discuss the design of the global in-memory cache. These will be discussed later in this course.
❔ We designed the TinyURL service based on the requirements that we discussed in the beginning. If we change those requirements, then it will affect the design of the service as well. Now, there is a question for you. If we allow anonymous users to create short URLs, then how will the design change? Let us know what you think in the discussion section.
❔ What do you think about how spam and malicious website links are handled?